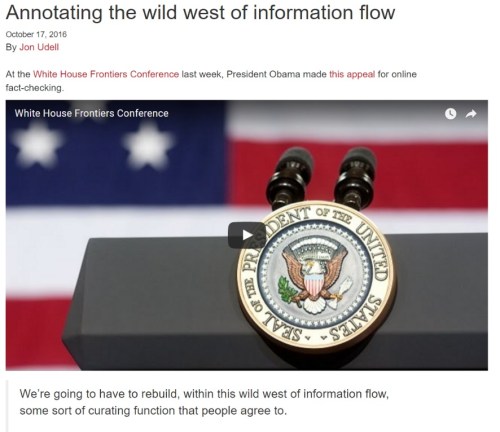
In 1997, at the first Perl Conference, which became OSCON the following year, my friend Andrew Schulman and I both gave talks on how the web was becoming a platform not only for publishing, but also for networked software.
Here’s the slide I remember from Andrew’s talk:
http://wwwapps.ups.com/tracking/tracking.cgi?tracknum=1Z742E220310270799
The only thing on it was a UPS tracking URL. Andrew asked us to stare at it for a while and think about what it really meant. “This is amazing!” he kept saying, over and over. “Every UPS package now has its own home page on the world wide web!”
It wasn’t just that the package had a globally unique identifier. It named a particular instance of a business process. It made the context surrounding the movement of that package through the UPS system available to UPS employees and customers who accessed it in their browsers. And it made that same context available to the Perl programs that some of us were writing to scrape web pages, extract their data, and repurpose it.
As we all soon learned, URLs can point to many kinds of resources: documents, interactive forms, audio or video.
The set of URL-addressable resources has two key properties: it’s infinite, and it’s interconnected. Twenty years later we’re still figuring out all the things you can do on a web of hyperlinked resources that are accessible at well-known global addresses and manipulated by a few simple commands like GET, POST, and DELETE.
When you’re working in an infinitely large universe it can seem ungrateful to complain that it’s too small. But there’s an even larger universe of resources populated by segments of audio and video, regions of images, and most importantly, for many of us, text in web documents: paragraphs, sentences, words, table cells.
So let’s stare in amazement at another interesting URL:
https://hyp.is/LoaMFCSJEee3aAMJuXhO-w/www.ics.uci.edu/~fielding/pubs/dissertation/software_arch.htm
Here’s what it looks like to a human who follows the link: You land on a web page, in this case Roy Fielding’s dissertation on web architecture, it scrolls to the place where I’ve highlighted a phrase, and the Hypothesis sidebar displays my annotation which includes a comment and a tag.

And here’s what that resource looks like to a computer when it fetches a variant of that link:
{
"body": [
{
"type": "TextualBody",
"value": "components: web resources\n\nconnectors: links\n\ndata: data",
"format": "text/markdown"
},
{
"type": "TextualBody",
"purpose": "tagging",
"value": "IAnnotate2017"
}
],
"target": [
{
"source": "https://www.ics.uci.edu/~fielding/pubs/dissertation/software_arch.htm",
"selector": [
{
"type": "XPathSelector",
"value": "/table[2]/tbody[1]/tr[1]/td[1]",
"refinedBy": {
"start": 82,
"end": 114,
"type": "TextPositionSelector"
}
},
{
"type": "TextPositionSelector",
"end": 4055,
"start": 4023
},
{
"exact": "components, connectors, and data",
"prefix": "tion of architectural elements--",
"type": "TextQuoteSelector",
"suffix": "--constrained in their relations"
}
]
}
],
"created": "2017-04-18T22:48:46.756821+00:00",
"@context": "http://www.w3.org/ns/anno.jsonld",
"creator": "acct:judell@hypothes.is",
"type": "Annotation",
"id": "https://hypothes.is/a/LoaMFCSJEee3aAMJuXhO-w",
"modified": "2017-04-18T23:03:54.502857+00:00"
}
The URL, which we call a direct link, isn’t itself a standard way to address a selection of text, it’s just a link that points to a web resource. But the resource it points to, which describes the highlighted text and its coordinates within the document, is — since February of this year — a W3C standard. The way I like to think about it is that the highlighted phrase — and every possible highlighted phrase — has its own home page on the web, a place where humans and machines can jointly focus attention.
If we think of the web we’ve known as a kind of fabric woven together with links, the annotated web increases the thread count of that fabric. When we weave with pieces of URL-addressable documents, we can have conversations about those pieces, we can retrieve them, we can tag them, and we can interconnect them.
Working with our panelists and others, it’s been my privilege to build a series of annotation-powered apps that begin to show what’s possible when every piece of the web is addressable in this way.
I’ll show you some examples, then invite my collaborators — Beth Ruedi from AAAS, Mike Caulfield from Washington State University Vancouver, Anita Bandrowski from SciCrunch, and Maryann Martone from UCSD and Hypothesis — to talk about what these apps are doing for them now, and where we hope to take them next.
Science in the Classroom
First up is a AAAS project called Science in the Classroom, a collection of research papers from the Science family of journals that are annotated — by graduate students — so teachers can help younger students understand the methods and outcomes of scientific research.

Here’s one of those annotated papers. A widget called the Learning Lens toggles layers of annotation and off.

Here I’ve selected the Glossary layer, and I’ve clicked on the word “distal” to reveal the annotation attached to it.

Now lets look behind the scenes:
Hypothesis was used to annotate the word “distal”. But Learning Lens predated the use of Hypothesis, and the Science in the Classroom team wanted to keep using Learning Lens to display annotations. What they didn’t want was the workflow behind it, which required manual insertion of annotations into HTML pages.
Here’s the solution we came up with. Use Hypothesis to create annotations, then use some JavaScript in Science in the Classroom pages to retrieve Hypothesis annotations and write them into the pages, using the same format that had been applied manually. The preexisting and unmodified Learning Lens JavaScript can then do what it does: pick up the annotations, assign color-coded highlights based on tags, and show the annotations when you click on the highlights.

What made this possible was a JavaScript library that helps with the heavy lifting required to attach an annotation to its intended target in the document.
That library is part of the Hypothesis client, but it’s also available as a standalone module that can be used for other purposes. It’s a nice example of how open source components can enable an ecosystem of interoperable annotation services.
DigiPo / EIC
Next up is a toolkit for student fact-checkers and investigative journalists. You’ve already heard from Mike Caulfield about the Digital Polarization Project, or DigiPo, and from Stefan Candea about the European Investigative Collaborations network. Let’s look at how we’ve woven annotation into their investigative workflows.

These investigations are both written and displayed in a wiki. This is a DigiPo example:
I did the investigation of this claim myself, to test out the process we were developing. It required me to gather a whole lot of supporting evidence before I could begin to analyze the claim. I used a Hypothesis tag to collect annotations related to the investigation, and you can see them in this Hypothesis view:

I can be very disciplined about using tags this way, but it’s a lot to ask of students, or really almost anyone. So we created a tool that knows about the set of investigations underway in the wiki, and offers the names of those pages as selectable tags.

Here I’ve selected a piece of evidence for that investigation. I’m going to annotate it, not by using Hypothesis directly, but instead by using a function in a separate DigiPo extension. That function uses the core anchoring libraries to create annotations in the same way the Hypothesis client does.

But it leads the user through an interstitial page that asks which investigation the annotation belongs to, and assigns a corresponding tag to the annotation it creates.

Back in the wiki, the page embeds the same Hypothesis view we’ve already seen, as a Related Annotations widget pinned to that particular tag:

I had so much raw material for this article that I needed some help organizing it. So I added a Timeline widget that gathers a subset of the source annotations that are tagged with dates.

To put something onto the timeline, you select a date on a page.

Then you create an annotation with a tag corresponding to the date.

Here’s what the annotation looks like in Hypothesis.
Over in the wiki, our JavaScript finds annotations that have these date tags and arranges them on the Timeline.
Publication dates aren’t always evident on web pages, sometimes you have to do some digging to find them. When you do find one, and annotate a page with it, you’ve done more than populate the Timeline in a DigiPo page. That date annotation is now attached to the source page for anyone to discover, using Hypothesis or any other annotation-aware viewer. And that’s true for all the annotations created by DigiPo investigators. They’re woven into DigiPo pages, but they’re also available for separate reuse and aggregation.

The last and most popular annotation-related feature we added to the toolkit is called Footnotes. Once you’ve gathered your raw material into the Related Annotations bucket, and maybe organized some of it onto the Timeline, you’ll want to weave the most pertinent references into the analysis you’re writing.

To do that, you find the annotation you gathered and use Copy to clipboard to capture the direct link.

Then you wrap that link around some text in the article:

When you refresh the page, here’s what you get. The direct link does what a direct link does: it takes you to the page, scrolls you to the annotation in context. But it can take a while to review a bunch of sources that way.
So the page’s JavaScript also creates a link that points down into the Footnotes section. And there, as Ted Nelson would say, and as Nate Angell for some reason hates hearing me say, the footnote is “transcluded” into the page so all the supporting context is right there.

One final point about this toolkit. Students don’t like the writing tools available in wikis, and for good reason, they’re pretty rough around the edges. So we want to enable them to write in Google Docs. We also want them to footnote their articles using direct links because that’s the best way to do it. So here’s a solution we’re trying. From the wiki you’ll launch into Google Docs where you can do your writing in a much more robust editor that makes it really easy to include images and charts. And if you use direct links in that Google Doc, they’ll still show up as Footnotes.
We’re not yet sure this will pan out, but my colleague Maryann Martone, who uses Hypothesis to gather raw material for her scientific papers, and who writes them in Google Docs, would love to be able to flow annotations through her writing tool and into published footnotes.
SciBot
Maryann is the perfect segue to our next example. Along with Anita Bandrowski, she’s working to increase the thread count in the fabric of scientific literature. When neuroscientists write up the methods used in their experiments, the ingredients often include highly specific antibodies. These have colloquial names, and even vendor catalog numbers, but they still lacked unique identifiers. So the Neuroscience Information Framework, NIF for short, has defined a namespace called RRID (research resource identifier), built a registry for RRIDs, and convinced a growing number of authors to mention RRIDs in their papers.

Here’s an article with RRIDs in it. They’re written directly into the text because the text is the scientific record, it’s the only artifact that’s guaranteed to be preserved. So if you’re talking about a goat polyclonal antibody, you look it up in the registery, capture its ID, and write it directly into the text. And if it’s not in the registry, please add it, you’ll make Anita very happy if you do!
The first phase of a project we call SciBot was about validating those RRIDs. They’re just freetext, after all, typed in by authors. Were the identifiers spelled correctly? Did they point to actual registry entries? To find out we built a tool that automatically annotates occurrences of RRIDs.

In this example, Anita is about to click on the SciBot tool, which launches from a bookmarklet, and sends the text of the paper to a backend service. It scans the text for RRIDs, looks up each one in the registry, and uses the Hypothesis API to create an annotation — bound to the occurrence in the text — that reports the results of the registry lookup.

Here the Hypothesis realtime API is showing that SciBot has created three annotations on this page.

And here are those three annotations, anchored to their occurrences in the page, with registry entries displayed in the sidebar.
SciBot curators review these annotations and use tags to mark which are valid. When some aren’t, and need attention, the highlight focuses that attention on a specific occurrence.

This hybrid of automatic entity recognition and interactive human curation is really powerful. Here’s an example where an antibody doesn’t have an RRID but should.
Every automatic workflow needs human exception handling and error correction. Here the curator has marked an RRID that wasn’t written into the literature, but now is present in the annotation layer.
These corrections are now available to train a next-gen entity recognizer. Iterating through that kind of feedback loop will be a powerful way to mine the implicit data that’s woven into the scientific literature and make it explicit.

Here’s the Hypothesis dashboard for one of the SciBot curators. The tag cloud gives you a pretty good sense of how this process has been unfolding so far.

Publishers have begun to link RRIDs to the NIF registry. Here’s an example at PubMed.
If you follow the ZIRC_ZL1 link to the registry, you’ll find a list of other papers whose authors used the same experimental ingredient, which happens to be a particular strain of zebrafish.

This is the main purpose of RRIDs. If that zebrafish is part of my experiment, I want to find who else has used it, and what their experiences have been — not just what they reported in their papers, but ideally also what’s been discussed in the annotation layer.
Of course I can visit those papers, and search within them for ZIRC_ZLI, but with annotations we can do better. In DigiPo we saw how footnoted quotes from source documents can transclude into an article. Publishers could do the same here.

Or we could do this. It’s a little tool that offers to look up an RRID selected in text.

It just links to an instance of the Hypothesis dashboard that’s pinned to the tag for that RRID.

Those search results offer direct links that take you to each occurrence in context.
Claim Chart
Finally, and to bring us full circle, I recently reconnected with Andrew Schulman who works nowadays as a software patent attorney. There’s a tool of his trade called a claim chart. It’s a two-column table. In column one you list claims that a patent is making, which are selections of text from the claims section of the patent. And in column two you assemble bits of evidence, gathered from other sources, that bear on specific claims. Those bits of evidence are selections of text in other documents. It’s tedious to build a claim chart, it involves a lot of copying and pasting, and the evidence you gather is typically trapped in whatever document you create.
Andrew wondered if an annotation-powered app could help build claim charts, and also make the supporting evidence web-addressable for all the reasons we’ve discussed. If I’ve learned anything about annotation, it’s that when somebody asks “Can you do X with annotation?” the answer should always be: “I don’t know, should be possible, let’s find out.”

So, here’s an annotation-powered claim chart.

The daggers at top left in each cell are direct links. The ones in the first column go to patent claims in context.

The ones in the second column go to related statements in other documents.

And here’s how the columns are related. When you annotate a claim, you use a toolkit function called Add Selection as Claim.

Your selection here identifies the target document (that is, the patent), the claim chart you’re building (here, it’s a wiki page called andrew_test), and the claim itself (for example, claim 1).

Once you’ve identified the claims in this way, they’re available as targets of annotations in other documents. From a selection in another document, you use Add Selection as Claim-Related.

Here you see all the claims you’ve marked up, so it’s easy to connect the two statements.

The last time I read Vannevar Bush’s famous essay As We May Think, this was the quote that stuck with me.
When statements in documents become addressable resources on the web, we can weave them together in the way Vannevar Bush imagined.