Update: See this post (with screencasts!)
Mike Caulfield’s Digital Polarization Initiative (DigiPo) is a template for a course that will lead students through exercises to analyze and fact-check news stories. The pedagogical approach Mike describes here is evolving; in parallel I’ve been evolving a toolkit to help students research and organize the raw materials of the analyses they’ll be asked to produce. Annotation is a key component of the toolkit. I’ve been working to integrate it into the fact-checking workflow in ways that complement the use of other tools.
We’re not done yet but I’m pleased with the results so far. This post is an interim report to summarize what we’ve learned so far about building an annotation-powered toolkit for fact checkers.
Here’s an example of a DigiPo claim to be investigated:
EPA Plans to Allow Unlimited Dumping of Fracking Wastewater in the Gulf of Mexico (see Occupy)
I start with no a priori knowledge of EPA rules governing release of fracking wastewater, and only a passing acquaintance with the cited source, occupy.com. So the first order of business is to marshal some evidence. Hypothesis is ideal for this purpose. It creates links that encapsulate both the URL of a page containing found evidence, and the evidence itself — that is, a quote selected in the page.
There’s a dedicated page for each DigiPo investigation. It’s a wiki, so you can manually include Hypothesis links as you create them. But fact-checking is tedious work, and students will benefit from any automation that helps them focus on the analysis.
The first step was to include Hypothesis as a widget that displays annotations matching the wiki id of the page. Here’s a standalone Hypothesis view that gathers all the evidence I’ve tagged with digipo:analysis:gulf_of_frackwater. From there it was an easy next step to tweak the wiki template so it embeds that view directly in the page:

That’s really helpful, but it still requires students to acquire and use the correct tag in order to populate the widget. We can do better than that, and I’ll show how later, but here’s the next thing that happened: the timeline.
While working through a different fact-checking exercise, I found myself arranging a subset of the tagged annotations in chronological order. Again that’s a thing you can do manually; again it’s tedious; again we can automate with a bit of tag discipline and some tooling.
If you do much online research, you’ll know that it’s often hard to find the publication date of a web page. It might or might not be encoded in the URL. It might or might not appear somewhere in the text of the page. If it does there’s no predictable location or format. You can, however, ask Google to report the date on which it first indexed a page, and that turns out to be a pretty good proxy for the publication date.
So I made another bookmarklet to encapsulate that query. If you were to activate it on one of my posts it would lead you to this page:
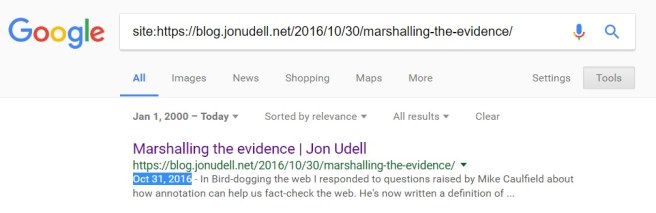
I wrote the post on Oct 30, Google indexed it on Oct 31, that’s close enough for our purposes.
I made another bookmarklet to capture that date and add it, as a Hypothesis annotation, to the target page.

With these tools in hand, we can expand the widget to include:
-
Timeline. Annotations on the target page with a googledate tag, in chronological order.
-
Related Annotations. Annotations on the target page with a tag matching the id of the wiki page.
You can see a Related Annotations view above, here’s a Timeline:

So far, so good, but as Mike rightly pointed out, this motley assortment of bookmarklets spelled trouble. We wouldn’t want students to have to install them, and in any case bookmarklets are increasingly unlikely to work. So I transplanted them into a Chrome extension. It presents the growing set of tools in our fact-checking toolkit as right-click options on Chrome’s context menu:

It also affords a nice way to stash your Hypothesis credentials, so the tools can save annotations on your behalf:

(The DigiPo extension is Chrome-only for now, as is the Hypothesis extension, but WebExtensions should soon enable broader coverage.)
With the bookmarklets now wrapped in an extension we returned to the problem of simplifying the use of tags corresponding to wiki investigation pages. Hypothesis tags are freeform. Ideally you’d be able to configure the tag editor to present controlled lists of tags in various contexts, but that isn’t yet a feature of Hypothesis.
We can, though, use the Digipo extension to add a controlled-tagging feature to the fact-checking toolkit. The Tag this Page tool does that:

You activate the tool from a page that has evidence related to a DigiPo investigation. It reads the DigiPo page that lists investigations, captures the wiki ids of those pages. and presents them in a picklist. When you choose the investigation to which the current page applies, the current page is annotated with the investigation’s wiki id and will then show up in the Related Annotations bucket on the investigation page.
While I was doing all this I committed an ironic faux pas on Facebook and shared this article. Crazy, right? I’m literally in the middle of building tools to help people evaluate stuff like this, and yet I share without checking. Why did I not take the few seconds required to vet the source, bipartisanreport.com?
When I made myself do that I realized that what should have taken a few seconds took longer. There’s a particular Google advanced query syntax you need in this situation. You are looking for the character string “bipartisanreport.com” but you want to exclude the majority of self-referential pages. You only want to know what other sites say about this one. The query goes like this:
bipartisanreport.com -site:bipartisanreport.com
Just knowing the recipe isn’t enough. Using it needs to be second nature and, even for me, it clearly wasn’t. So now there’s Google this Site:

Which produces this:

It’s ridiculously simple and powerful. I can see at a glance that bipartisanreport.com shows up on a couple of lists of questionable sites. What does the web think about the sites that host those lists? I can repeat Google this Site to zoom in on them.
Another tool in the kit, Save Facebook Share Count, supports the sort of analysis that Mike did in a post entitled Despite Zuckerberg’s Protests, Fake News Does Better on Facebook Than Real News. Here’s Data to Prove It.
How, for example, has this questionable claim propagated on Facebook? There’s a breadcrumb trail in the annotation layer. On Dec 26 I used Save Publication Date to assign the tag googledate:2016-08-31, and on the same day I used Save Facebook Share Count to record the number of shares reported by the Facebook API. On Dec 30 I again used Save Facebook Share Count. Now we can see that the article is past its sell-by date on Facebook and never was highly influential.

Finally there’s Summarize Quotes, which arose from an experiment of Mike’s to fact-check a single article exhaustively. Here’s the article he picked, along with the annotation layer he created:

Some of the annotations contain Hypothesis direct links to related annotations. If you open this annotation in the Politico article, for example, you can follow Hypothesis links to related annotations on pages at USA Today and Science.
These transitive annotations are potent but it gets to be a lot of clicking around. So the most experimental of the tools in the kit, Summarize Quotes, produces a page like this:

This approach doesn’t feel quite right yet, but I suspect there’s something there. Using these tools you can gather a lot of evidence pretty quickly and easily. It then needs to be summarized effectively so students can reason about the evidence and produce quality analysis. The toolkit embodies a few ways to do that summarization, I’m sure more will emerge.
A “Has this site been mentioned on Snopes? Show me.” tool might be useful.
Indeed! Let’s try that, thanks.
Here is a simple way to collect web pages with more technical content. The form is set up to search with added words related to “controversy” and “forms of support”.
Copy the file, rename from TXT to HTML, enter your search term and choose the added words.
https://dl.dropboxusercontent.com/u/40379370/ControversyExplorer.txt
Permission granted to modify the form which I cribbed from an early edition of “Google Hacks” by Tara Calishain.
The idea traces back to my article “Do Search Engines Suppress Controversy?” (First Monday, January 2004). Now we know.
Thanks Susan! It’s nice to see how a thing like that can, by sticking to simple and basic techniques, remain useful.
Reblogged this on Canary in the coalmine and commented:
This reblog is thanks to Jon Udell, a very tech-minded blogger I follow. He is working on an application that looks promising. It might just make it easier and quicker to determine fake news from real news, well, at least those tricky ones. (Well, until they find another way around it…)
Until then… here’s some of my tips and how I attempt* to determine a story’s veracity (truth):
The general rules still apply – any story is suspect if one or all of the following are true:
• The language used in the article is biased and/or overly emotional. i.e. “ARE YOUR CHILDREN BEING TAUGHT ISLAM IN PUBLIC SCHOOL?!” (lol)
• Sources are not cited in the text or at the end of the article.
• There is no posting date anywhere and/or the posting date is recent and not a repost of old news, re-hyped for ad-click purposes. (NOTE: the app mentioned above with search the html code for you for the original posting date… yay!)
• The website address is misspelled, truncated, and/or has an additional ‘dot-something’ at the end. (i.e. http://www.cnn.com.co is FAKE)
• The news site is unfamiliar. (i.e. ‘liberty presshouse’ or some weird conglomeration thereof…) If I’ve never heard of it, I immediately start to check all the more common news sites for record of the same or a similar story.
All I will add is that, yes, as of today’s date, press houses and media outlets have been forced into a comic book hero scenario since the inception of Fox News. Superman created Lex Luther, right? The Joker created Batman… the list is long…
So, yes… Fox News forced news agencies to represent the ‘other side’… but:
– The very concept of FREE PRESS, is a LIBERAL ideal.
– There is a difference between left-leaning and full-out Liberal. Yes, NPR is left-leaning, but has had some of the more insightful articles. Yes, CNN is still struggling to find its’ footing in the left vs. right playing field and more often than not, take NO stand – even when it is appropriate to…
I hope this tool helps us to start to separate fake news from real news…
For now… TURN OFF THE NEWS FEED ON FACEBOOK. It will only upset you…
And to the media… CAN WE PLEASE JUST GO BACK TO THE EVENING NEWS HOUR? And lose all the filler crap?
*Yes, even I make mistakes… but I would rather err on the side of an overly hyped story being FALSE than getting upset over nothing and having to stay upset just to save face…
That’s a nice set of heuristics!
My personal view is that I hope DIgipo will not only help students learn to separate fake from real news, but also help them to analyze the real news by developing the habit of digging into and documenting the sources behind the news.
Even more grandly, I hope it is one of a series of initiatives that teach a generation how to engage in evidence-based discourse.
Yes! I was so glad to see your post – it’s a welcome addition to my arsenal. My own personal agenda/push is for liberal studies to be re-introduced into the curriculum. Critical thinking skills are a dying art. I re-watched the movie “Idiocracy” a few weeks ago… and oh my gosh – don’t watch it, it was as terrifying now as it was ridiculous and funny back in aught-6.
And thanks for the vote of confidence on my research methods, despite the flaw in at least one (typo, lol). It’s to the point now that I’ve developed a sort of instinct for fake, or at the least, ‘questionable’ news… And have realized lately that one problem even critical thinking skills can’t fix is when stories are hijacked and reposted with hyped-up headlines by fake news sites and/or bloggers looking for ad-clicks… and most recently by the news agencies themselves! (NPR and a few others are bad for re-posting and re-hashing the same stories months later… *sigh* and giving it some new sexy headline.)
Thanks again! I will keep checking in, and can suggest it to the schools here if need be… (I can only do so much teaching my own kids – it needs to be part of the Library Skills curriculum!)
Cheers! :-)