Here’s a glimpse of a capability I’ve long imagined:
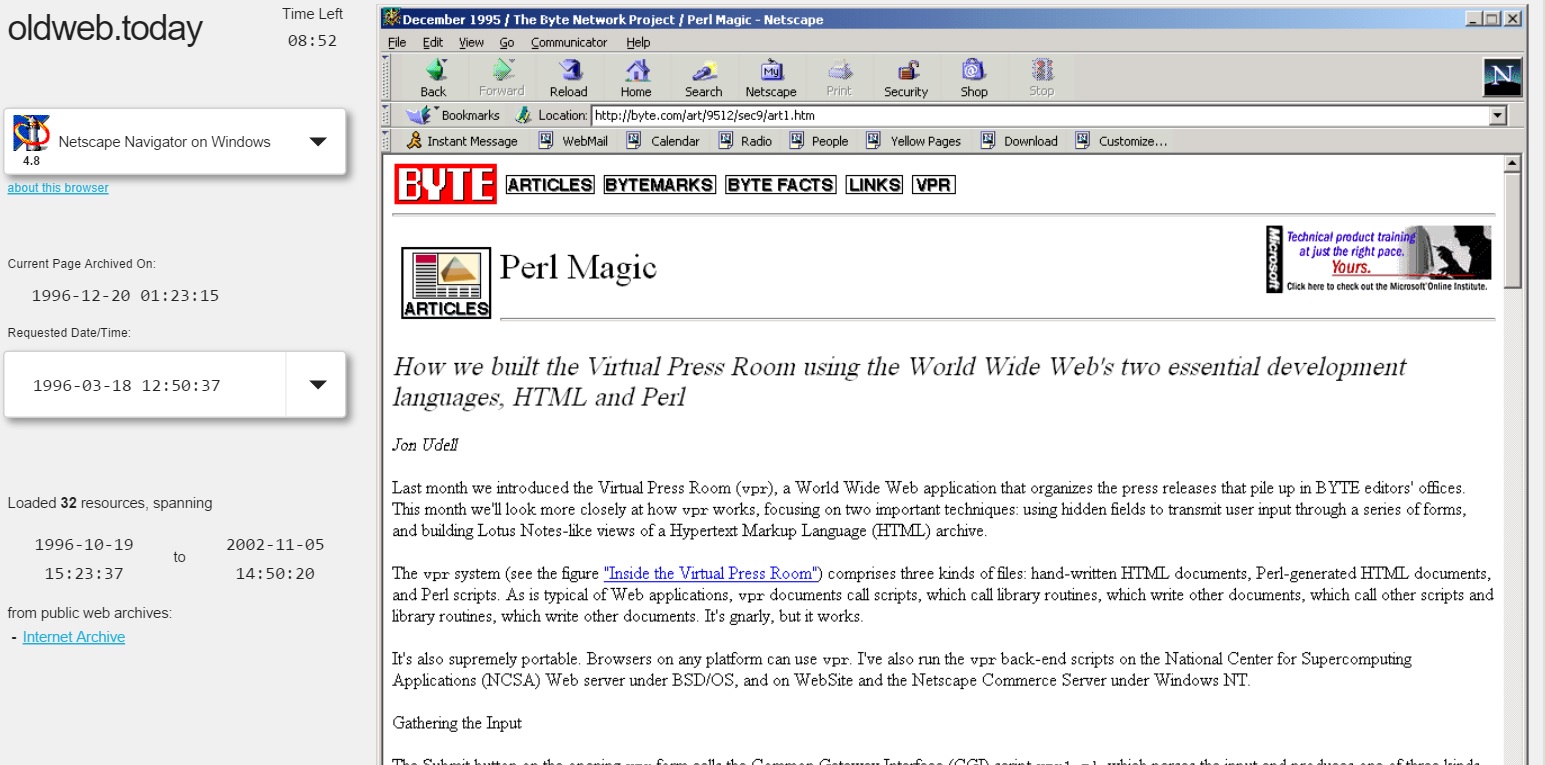
It’s a picture of me browsing my December 1995 BYTE column, using the same browser — Netscape Navigator 4.0 — that I used when I wrote the column 20 years ago. You can try this yourself, for any archived website, using oldweb.today, a new project by the brilliant web archivist Ilya Kreymer. I’ve gotten to know Ilya by way of Hypothesis. We use his pywb proxy (hosted at via.hypothes.is) to inject our annotation software into web pages.
The rhizome.org blog has the scoop on oldweb.today’s lightweight emulation strategy. It’s a harbinger of things to come. Much of our cultural heritage — our words, our still and moving pictures, our sounds, our data — is born digital. Soon almost everything will be. It won’t be enough to archive our digital artifacts. We’ll also need to archive the software that accesses and renders them. And we’ll need systems that retrieve and animate that software so it, in turn, can retrieve and animate the data.
The enabling technologies are coming together quickly. Cloud-based computing keeps getting better and cheaper. The Docker revolution makes it radically easier to save and recreate complex software configurations. For the most part we benefit from this new infrastructure without noticing it or thinking about it, and that’s a good thing.
With oldweb.today, though, it’s hard not to notice or think about the infrastructure that delivers this magic into your browser. That’s a good thing too. It’s useful for everyone to have some awareness of what’s required to experience cultural artifacts with original fidelity, or to reliably reproduce scientific experiments. Ilya’s project isn’t only a great way to revisit the early web. It’s also a signpost on the road to these futures.
Excellent articulation of the need as well as some helpful efforts in the works. Thanks Jon!