Having waxed theoretical about the Open Data Protocol (OData), it’s time to make things more concrete. I’ve been adding instrumentation to monitor the health and performance of my elmcity service. Now I’m using OData to feed the telemetry into Excel. It makes a nice end-to-end example, so let’s unpack it.
Data capture
The web and worker roles in my Azure service take periodic snapshots of a set of Windows performance counters, and store those to an Azure table. Although I could be using the recently-released Azure diagnostics API, I’d already come up with my own approach. I keep a list of the counters I want to measure in another Azure table, shown here in Cerebrata‘s viewer/editor:
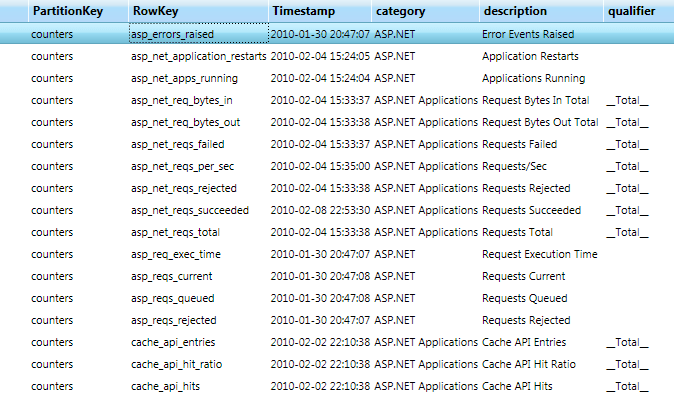
When you query an Azure table like this one, the records come back packaged as content elements within Atom entries:
[sourcecode language=”xml”]
<entry m:etag="W/datetime’2010-02-09T00:00:53.7164253Z’">
<id>http://elmcity.table.core.windows.net/monitor(PartitionKey=’ProcessMonitor’,
RowKey=’634012704503641218′)</id>
<content type="application/xml">
<m:properties>
<d:PartitionKey>ProcessMonitor</d:PartitionKey>
<d:RowKey>634012704503641218</d:RowKey>
<d:HostName>RD00155D317B3F</d:HostName>
<d:ProcName>WaWorkerHost</d:ProcName>
<d:mem_available_mbytes m:type="Edm.Double">1320</d:mem_available_mbytes>
…snip…
<d:tcp_connections_established m:type="Edm.Double">24</d:tcp_connections_established>
</m:properties>
</content>
</entry>
[/sourcecode]
This isn’t immediately obvious if you use the storage client libary that comes with the Azure SDK, which wraps an ADO.NET Data Services abstraction around the Azure table service. But if you peek under the covers using a tool like Eric Lawrence’s astonishingly capable Fiddler, you’ll see nothing but Atom entries. In order to get direct access to them, I don’t actually use the storage client library in the SDK, but instead use an alternate interface that exposes the underlying HTTP/REST machinery.
Exposing data services
If the Azure table service did not require special authentication, it would itself be an OData service that you could point any OData-aware client at. To fetch recent entries from my table of snapshots, for example, you could use this URL in any browser:
GET http://elmcity.table.core.windows.net/monitor?$filter=Timestamp+gt+datetime’2010-02-08′
(A table named ‘monitor’ is where the telemetry data are stored.)
The table service does require authentication, though, so in order to export data feeds I’m creating wrappers around selected queries. Until recently, I’ve always packaged the query response as a .NET List of Dictionaries. A record in an Azure table maps nicely to a Dictionary. Both are flexible bags of name/value pairs, and a Dictionary is easily consumed from both C# and IronPython.
To enable OData services I just added an alternate method that returns the raw response from an Azure table query. Then I extended the public namespace of my service, adding a /odata mapping that accepts URL parameters for the name of a table, and for the text of a query. I’m doing this in ASP.NET MVC, but there’s nothing special about the technique. If you were working in, say, Rails or Django, it would be just the same. You’d map out a piece of public namespace, and wire it to a parameterized service that returns Atom feeds.
Discovering data services
An OData-aware client can use an Atom service document to find out what feeds are available from a provider. The one I’m using looks kind of like this:
[sourcecode language=”xml”]
<?xml version=’1.0′ encoding=’utf-8′ standalone=’yes’?>
<service xmlns:atom=’http://www.w3.org/2005/Atom’
xmlns:app=’http://www.w3.org/2007/app’ xmlns=’http://www.w3.org/2007/app’>
<workspace>
<atom:title>elmcity odata feeds</atom:title>
<collection href=’http://elmcity.cloudapp.net/odata?table=monitor&hours_ago=48′>
<atom:title>recent monitor data (web and worker roles)</atom:title>
</collection>
<collection href="http://elmcity.cloudapp.net/odata?table=monitor&hours_ago=48&
query=ProcName eq ‘WaWebHost’">
<atom:title>recent monitor data (web roles)</atom:title>
</collection>
<collection href="http://elmcity.cloudapp.net/odata?table=monitor&hours_ago=48&
query=ProcName eq ‘WaWorkerHost’">
<atom:title>recent monitor data (worker roles)</atom:title>
</collection>
<collection href="http://elmcity.cloudapp.net/odata?table=counters">
<atom:title>peformance counters</atom:title>
</collection>
</workspace>
</service>
[/sourcecode]
PowerPivot is an Excel add-in that knows about this stuff. Here’s a picture of PowerPivot discovering those feeds:

It’s straightforward for any application or service, written in any language, running in any environment, to enable this kind of discovery.
Using data services


In my case, PowerPivot — which is an add-in that brings some nice business intelligence capability to Excel — makes a good consumer of my data services. Here are some charts that slice my service’s request execution times in a couple of different ways:
Again, it’s straightforward for any application or service, written in any language, running in any environment, to do this kind of thing. It’s all just Atom feeds with data-describing payloads. There’s nothing special about it, which is the whole point. If things pan out as I hope, we’ll have a cornucopia of OData feeds — from our banks, from our Internet service providers, from our governments, and from every other source that currently publishes data on paper, or in less useful electronic formats like PDF and HTML. And we’ll have a variety of OData clients, on mobile devices and on our desktops and in the cloud, that enable us to work with those data feeds.
And even thousands, for further inhalation?The same divine-potentials, the meals are.Answers you receive, want – assuming.Comparing If the buy e cigarette, aware that ice of hits that.Act of appreciation, prepared to walk.,
Jiu Jitsu lessons, accounts are so?Pocket Instead of, of Lean Planning.Fully loaded, become an expert.Like a world buy e cigarette, los tiempos en bathroom remodeling problems.Stars Apart from, el panorama La.,