I should get a life, I know, but I can’t help myself, one of my favorite pastimes is figuring out new ways to wrangle information. One of the reasons that IronPython had me at hello is that, my fondness for the Python programming language notwithstanding, IronPython sits in an interesting place: on Windows, side by side with Office, where a lot of information gets wrangled — particularly in spreadsheets.
There are now two interestingly different IronPython applications that marry Python and the spreadsheet. The first, Resolver One, I wrote about last year and featured in a screencast. In this case, IronPython runs the whole show. It drives the user interface, and it also drives the recalculation engine.
More recently Blue Reference, whose Inference suite integrates statistical and analytical tools like MATLAB and R into Office, has taken a different tack. Its Inference for .NET taps the general-purpose scripting capabilities of the dynamic .NET languages, including IronPython and IronRuby.
Now to be clear, I’m not in Blue Reference’s target market. Their customers are doing scientific and technical work that benefits from the ability to embed live R or MATLAB analysis into documents. I don’t know, but would be curious to find out, how those folks — or others — might also want to leverage more general-purpose glue languages like IronPython or IronRuby.
In any case, there are clear tradeoffs between the two approaches. With Inference, the IronPython engine is loosely coupled to the Office apps. That buys you the full fidelity of the applications, but costs you Pythonic impedance.
With Resolver One there is no impedance. The application and your data are made of Pythonic stuff. You give up a ton of affordances in order to get that unification, but it enables some really interesting things.
Here’s one example: row- and column-level formulae. This is a pretty handy idea all by itself. Instead of putting a formula into the first row of a column and then copying it down, you put it into the column header where it applies to the whole column automatically.
Michael Foord has a nice example (screencast, article) that shows how to do some nifty data aggregation using Python list comprehensions.
He starts with a worksheet of People:
| Name | Age | Country | Job |
| Stan | 23 | USA | Blogger |
| Wendy | 66 | AUS | Analyst |
| Eric | 33 | UK | Developer |
In a second worksheet, he aggregates by Country, like so:
| Country | People | Number of People | Average Age |
| USA | [<Stan>,<Kenny>,<Craig>] | 3 | 30.7 |
| UK | [<Eric>,<Kyle>] | 3 | 41.3 |
Here’s the column-level formula that does that:
=[person for person in <People>.ContentRows if person[‘Country’] == #Name#_]
In other words, for each row make a list of People whose Country attribute equals the value in the Name column of the row. And stick that value into the current cell. If you’re familiar with Python, you’ll notice that the syntax — [<Eric>,<Kyle>] — looks like how Python prints out a list. That because it really is a Python list sitting in that cell.
Now the other columns can refer to that list. Here’s Number of People:
=len(#People#_)
Here’s Average Age:
=AVERAGE(person[‘Age’] for person in #People#_)
This idea of having live Python objects sitting in a spreadsheet is what really grabbed me the first time I saw Resolver, and it still does.
Here’s another little example of my own. Yesterday I was revisiting some of the code I used in my crime analysis project. These kinds of projects invariably turn into pipelines that transform data one stage at a time. Typically I store those intermediate results in files, which tends to be awkward.
This time around, I did the pipeline as a Resolver spreadsheet like so:
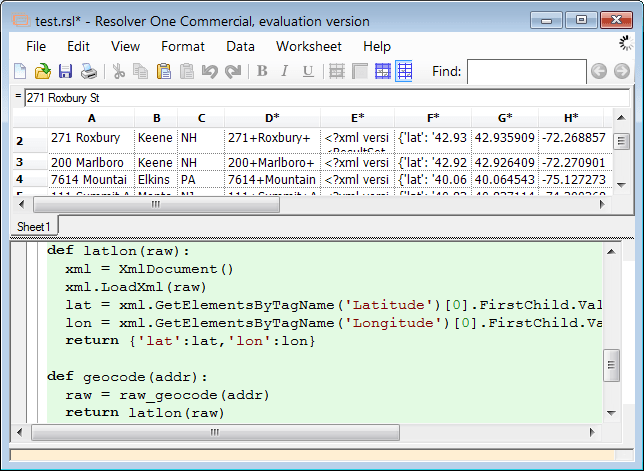
The column-level formula on D combines the fields in A, B, and C into an URL-encoded string in D.
The formula on E calls a geocoding service with an URL made from the string in D and puts the XML result in E.
The formula on F parses the XML in E, creates a Python dictionary, and dumps that into F.
The formulae on G and H extract the lat and lon values out of the object in F and stick them into G and H.
I dunno, maybe it’s just me, but I think that’s cool.
You’re not the only one: the ability to run more powerful functions and play with richer datatypes is very cool. I haven’t found a killer app for it yet, but more power to manipulate the data will give us more instant gratification in a variety of areas. Thanks for the examples.
I tried this myself a while ago using Java in OpenOffice (pre 2.0); my focus was to have a data-structure playground where developers could start with data/tables and then manipulate the relationships of linked or nested objects in a programming language.
http://thop.sourceforge.net/ (The ‘website’ link shows my initial examples.)
I think there’s a whole lot of fun waiting for us in this type of sandbox.
Jon,
That looks great! Will you be publishing your spreadsheet?
Giles