In Mapping the wider fediverse I showed how a new table added to the Mastodon plugin — mastodon_domain_block — enables queries that find which servers are moderating which other servers. For example, here are servers on nerdculture.de‘s list of offenders.
select server, domain, severity from mastodon_domain_block where server = 'https://nerdculture.de' +------------------------+--------------------------------+----------+ | server | domain | severity | +------------------------+--------------------------------+----------+ | https://nerdculture.de | roysbeer.place | silence | | https://nerdculture.de | *.10minutepleroma.com | suspend | | https://nerdculture.de | *.activitypub-troll.cf | suspend | ...snip... | https://nerdculture.de | shitposter.club | suspend | | https://nerdculture.de | wolfgirl.bar | suspend | | https://nerdculture.de | www2.gabbers.me | suspend | +------------------------+--------------------------------+----------+
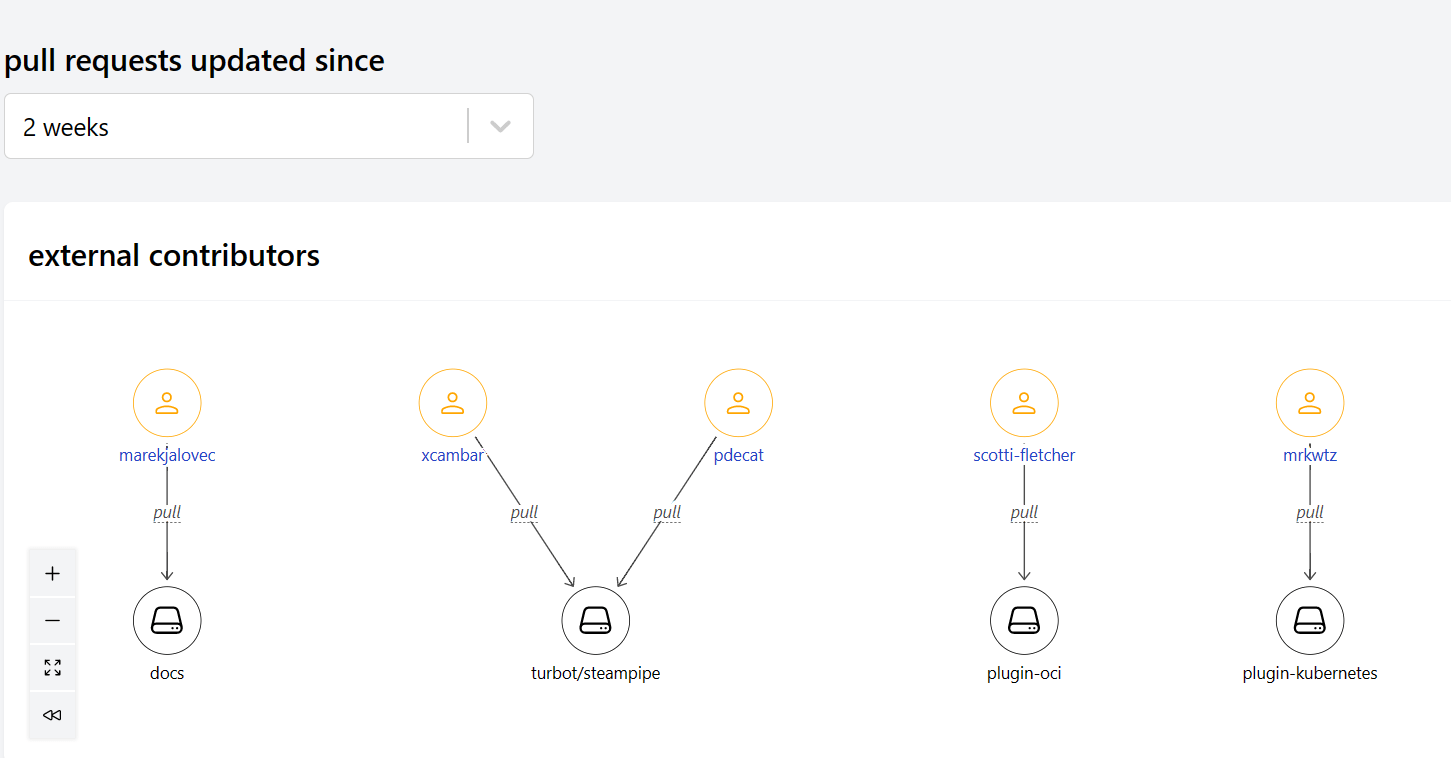
I used the new query pattern to build a dashboard to report, for each server in the home timeline:
- The list of blocking servers.
- The count of blocked servers for each blocking server.
- The list of blocking servers for each blocked server, and the count of those blocking servers.
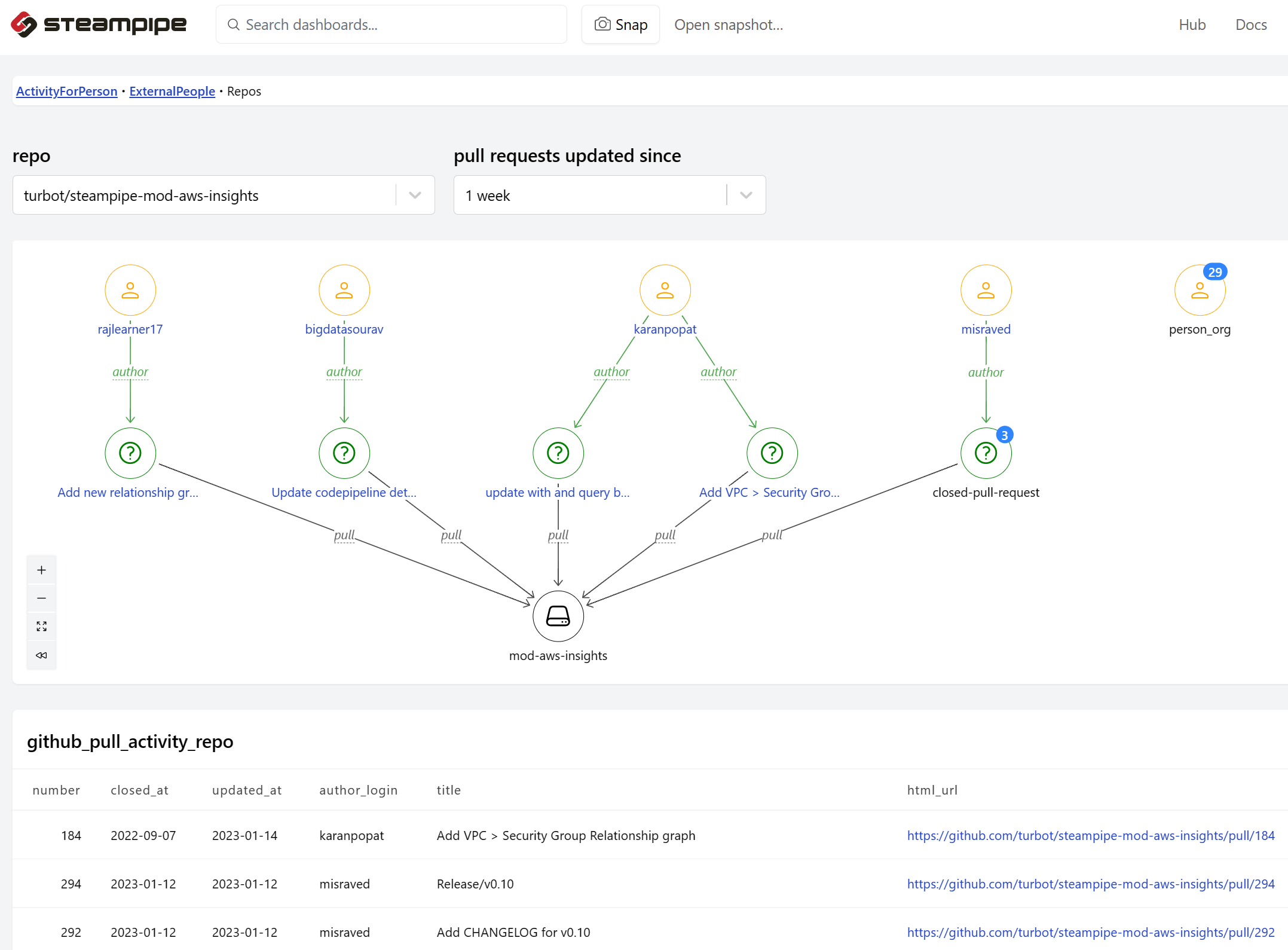
This was a good start, but I had a hunch that relationship graphs would reveal non-obvious connections among these servers. And indeed they do! Here’s a view of the new graph-enriched dashboard.

The left pane shows the blocked servers shunned by a blocking server selected from those in the home timeline. The right pane has the inverse view: the blocking servers that shun a selected blocked server. These were the two categories I defined for the first iteration of these graphs.
category "blocking_server" {
color = "darkgreen"
icon = "server"
}
category "blocked_server" {
color = "darkred"
icon = "server"
}
Here’s the code for one of the graphs.
graph {
node {
base = node.blocking_server
}
node {
base = node.blocked_server
}
node {
base = node.blocked_and_blocking_server
}
edge {
args = [ self.input.blocking_server.value ]
base = edge.match_blocked_server
}
edge {
args = [ self.input.blocking_server.value ]
base = edge.match_blocking_server
}
}
Here is the definition of node.blocking_server, which refers to category.blocking_server.
node "blocking_server" {
category = category.blocking_server
sql = <<EOQ
with servers as (
select distinct
blocking_server,
blocked_server
from
blocking_servers(${local.limit})
)
select
blocking_server as id,
blocking_server as title
from
servers
order by
blocking_server
EOQ
}
The FROM clause calls blocking_servers(), a set-returning function defined like so.
create or replace function public.blocking_servers(max int) returns table (
blocking_server text,
blocked_server text
) as $$
with servers as (
select distinct
server as domain,
'https://' || server as server_url
from
mastodon_toot
where
timeline = 'home'
limit max
),
blocking_and_blocked as (
select
s.domain as blocking_domain,
d.domain as blocked_domain
from
servers s
join
mastodon_domain_block d
on
s.server_url = d.server
)
select
blocking_domain,
blocked_domain
from
blocking_and_blocked
order by
blocking_domain, blocked_domain
$$ language sql
I thought these ingredients would suffice. But when I began poking around in the graphs made with these definitions, infosec.exchange behaved strangely. Someties it would appear as a blocking server, other times as a blocked server. I was missing a category!
category "blocked_and_blocking_server" {
color = "orange"
icon = "server"
}
As you can see in the graph, infosec.exchange not only blocks 73 servers, it is also blocked by two servers: religion.masto.host and weatherishappening.net. Why?
weatherishappening.net calls infosec.exchange a “HOSTING DEATH SPIRAL FASCIST ORGANIZATION” and blocks it with “Limited” severity.
religion.masto.host blocks infosec.exchange at the “Suspended” level, but does not explain why (“Reason not available”).
Although those servers could, in turn, be blocked by others, no such blocks appear in the block lists of my immediate server neighborhood.
> select count(*) from blocking_servers(100) where blocked_server = 'weatherishappening.net' +-------+ | count | +-------+ | 0 | +-------+ > select count(*) from blocking_servers(100) where blocked_server = 'religion.masto.host' +-------+ | count | +-------+ | 0 | +-------+
There is another switch hitter in my neighborhood, though. c.im is blocked by me.dm and octodon.social.

Why?
me.dm (Medium) has “Suspended” c.im for “Hate speech”.
octodon.social has “Suspended” c.im for “Reason not available”.
When the opinions and policies of your server differ from those of mine, we see different realities through our respective lenses. Could such fragmentation drive the fediverse-curious back into arms of Big Social? I’m sure that will happen — indeed is happening — to some degree.
But I hope that some of us, at least, will learn to thrive in diverse networks of online communities, aware of the kaleidoscopic interplay of filters but not overwhelmed by it. That skill will serve us well IRL too. To acquire it, we’ll need to visualize the operation of our filters. One great way to do that: SQL queries that drive relationship graphs.
—
1 https://blog.jonudell.net/2022/11/28/autonomy-packet-size-friction-fanout-and-velocity/
2 https://blog.jonudell.net/2022/12/06/mastodon-steampipe-and-rss/
3 https://blog.jonudell.net/2022/12/10/browsing-the-fediverse/
4 https://blog.jonudell.net/2022/12/17/a-bloomberg-terminal-for-mastodon/
5 https://blog.jonudell.net/2022/12/19/create-your-own-mastodon-ux/
6 https://blog.jonudell.net/2022/12/22/lists-and-people-on-mastodon/
7 https://blog.jonudell.net/2022/12/29/how-many-people-in-my-mastodon-feed-also-tweeted-today/
8 https://blog.jonudell.net/2022/12/31/instance-qualified-mastodon-urls/
9 https://blog.jonudell.net/2023/01/16/mastodon-relationship-graphs/
10 https://blog.jonudell.net/2023/01/21/working-with-mastodon-lists/
11 https://blog.jonudell.net/2023/01/26/images-considered-harmful-sometimes/
12 https://blog.jonudell.net/2023/02/02/mapping-the-wider-fediverse/
13 https://blog.jonudell.net/2023/02/06/protocols-apis-and-conventions/
14 https://blog.jonudell.net/2023/02/14/news-in-the-fediverse/
15 https://blog.jonudell.net/2023/02/26/mapping-people-and-tags-on-mastodon/
16 https://blog.jonudell.net/2023/03/07/visualizing-mastodon-server-moderation/
17 https://blog.jonudell.net/2023/03/14/mastodon-timelines-for-teams/
18 https://blog.jonudell.net/2023/04/03/the-mastodon-plugin-is-now-available-on-the-steampipe-hub/
19 https://blog.jonudell.net/2023/04/11/migrating-mastodon-lists/
20 https://blog.jonudell.net/2023/05/24/when-the-rubber-duck-talks-back/


























































{kind=link}
{kind=link}